



Introduction▲
Dans un article précédentStructure des fichiers OpenXML, nous avons fait connaissance avec la structure interne d'un paquetage OpenXML, il est temps de passer à la mise en oeuvre de toutes ces connaissances, au travers de la création d'un framework écrit en PHP donnant l'accès au contenu de ces fichiers. L'objectif principal de ce framework est de permettre au développeur qui l'utilise l'accès au contenu d'un document OpenXML au travers d'une API simple, et que lui soit masquée toute la complexité de la structure interne du paquet.
Le framework qui va être décrit dans les sections qui suivent, bien que tout à fait fonctionnel, n'a pas pour vocation à être utilisé en production, mais à illustrer les concepts que nous avons étudiés, et éventuellement à servir de base à vos propres développements.
1. Spécifications techniques & pré-requis▲
Pour garder au code de notre framework une relative simplicité et un rôle didactique, nous limiterons son rôle à la lecture des documents OpenXML, en laissant de côté leur création et leur modification.
Les fonctionnalités du framework se résumeront à cette liste :
- Reconnaissance automatique des documents OpenXML bureautiques de Office 2007 (Word, Excel)
- Accès aux métadonnées des documents
- Accès aux propriétés des documents
- Affichage d'un extrait (preview) au format HTML des documents
L'implémentation de ces fonctionnalités va nécessiter beaucoup de manipulations liées à XML. L'extension SimpleXML semble
être la candidate idéale pour répondre à ces besoins, tout en maîtrisant la complexité et la longueur du code. Cependant,
si SimpleXML est parfait pour manipuler des documents XML au schéma assez simple, à l'instar de ceux contenant les métadonnées
et les propriétés du document OpenXML, son utilisation se révèlera problématique lorsqu'il s'agira de générer l'extrait en
HTML du document, obtenu à partir du document XML principal (main part) et dont le schéma est particulièrement complexe.
Pour éviter la gageure d'avoir à accéder à un contenu en WordprocessingML ou en SpreadsheetML avec SimpleXML, nous mettrons
donc en oeuvre une solution à base de feuilles de style écrites en XSLT.
Un document OpenXML de Office 2007 étant une arborescence de fichiers contenue dans un paquetage zippé, il nous faudra un outil pour accéder à n'importe lequel de ces fichiers et de façon à ce que la gestion interne du format Zip (décompression) soit la plus transparente et la plus simple possible pour le code client, et de préférence sans qu'il soit nécessaire de décompresser le paquetage sur le système de fichier local. Parmi les outils Zip mis à disposition par PHP, la classe ZipArchive remplit toutes ces conditions.
Enfin, pour assurer à notre framework robustesse et extensibilité, les classes qui vont le constituer se doivent de respecter les règles de l'art actuelles en matière de POO (encapsulation, visibilité, héritage, etc.), ce qui exclut l'usage de PHP4, dont l'implémentation objet est trop rudimentaire.
En résumé, la plateforme idéale pour notre framework est la version 5.2 ou supérieure de PHP, avec les extensions XSL et ZipArchive activées.
Pour Windows, assurez-vous que ces deux lignes sont présentes dans php.ini :
extension=php_xsl.dll
extension=php_zip.dll
Pour Unix/Linux, PHP doit être configuré avec les options --with-xsl et --enable-zip.
2. La structure du framework▲
Les types de documents Office gérés par notre framework, soit Word et Excel, disposent chacun d'une classe dédiée dans notre framework, respectivement nommées WordDocument et ExcelWorkbook. Chaque instance (objet) de ces classes représente une instance d'un document OpenXML qui lui est présentée sous la forme d'un objet ZipArchive. Les méthodes présentées par ces classes permettent l'accès en lecture seule aux propriétés du document, et l'affichage de l'extrait (preview) du document.
Ces 2 classes vont dériver d'une classe mère OpenXMLDocument abstraite, qui va contenir le code de gestion de la structure interne du paquet, et les méthodes d'accès aux métadonnées du document (rappelons que les métadonnées ne dépendent pas du type de document Office auquel elles font référence, elles sont communes à tous les fichiers OpenXML), ainsi que le code permettant la transformation XSLT.
Parmi les fonctionnalités mentionnées dans les spécifications techniques, il y a la reconnaissance automatique par le framework du type de document Office. Il faut éviter de se retrouver dans le cas où par exemple le code client tente de créer une instance de WordDocument alors que le document OpenXML sous-jacent est un classeur Excel... Pour cela, le framework adopte le patron de conception Fabrique (factory), qui répond parfaitement à cette problématique. En présence d'un document OpenXML, le code client, au lieu d'instancier lui-même une des 2 classes de document, va passer le nom du document à la méthode statique getDocument() de la classe OpenXMLDocumentFactory qui va se charger de détecter le type de document et d'instancier la classe ad hoc, et de la lui renvoyer.
Il est à noter que ce dispositif est contournable par le développeur qui peut malgré tout persister à instancier lui-même une de ces classes ; il n'existe pas en PHP comme en Java de visibilité limitée au "package" qui, appliquée aux constructeurs des classes filles de OpenXMLDocument, les contraindraient à n'être instanciées que par la fabrique. Une petite faiblesse du modèle OO de PHP5 qui gagnerait, à mon avis, à être corrigée dans une version ultérieure...
En ce qui concerne la gestion des erreurs internes à notre Framework, elle est assurée par deux classes dérivées de la classe Exception : OpenXMLException et OpenXMLFatalException. Bien qu'ayant des implémentations similaires, elles n'interviennent pas dans les mêmes cas de figure : OpenXMLException est déclenchée en cas d'erreur logique intervenant lors de l'interrogation de la structure du paquet (absence de l'URI recherchée dans un fichier de relations, par exemple), tandis que OpenXMLFatalException est déclenchée par une erreur d'entrées/sorties, ou lors d'une erreur intervenant lors d'un parsing XML. OpenXMLException, au contraire de OpenXMLFatalException, ne désigne pas forcément une erreur grave devant arrêter l'arrêt du traitement. Ainsi, la tentative de lire les métadonnées d'un document qui n'en comporte pas (dans le tableau de la section 1.4.2 cette partie est déclarée optionnelle) ne déclenchera qu'une exception OpenXMLException. Dans l'état actuel du framework, les exceptions OpenXMLException sont gérées en interne par le framework, et seules les exceptions OpenXMLFatalException parviendront jusqu'au code client.
La structure de notre framework est modélisée dans ce diagramme de classes (les classes des exceptions ne figurent pas sur le diagramme) :
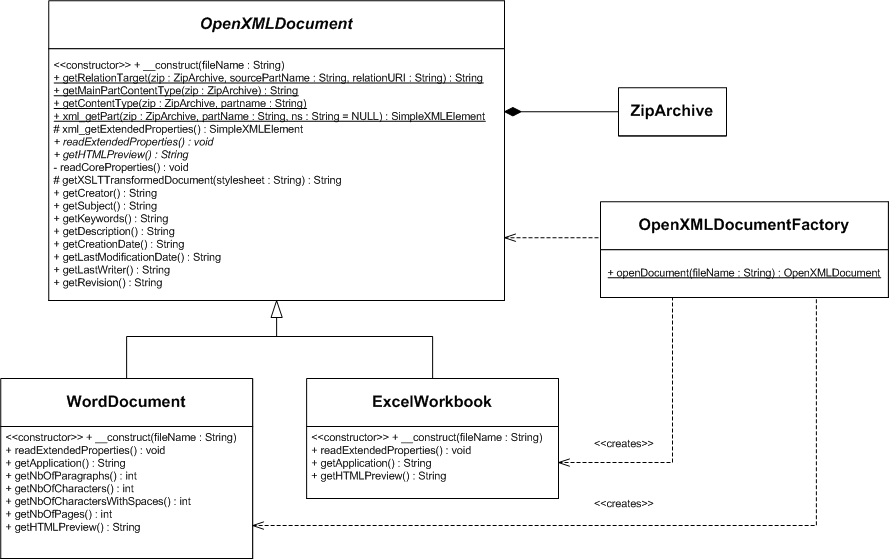
On remarquera que toutes les méthodes de la classe OpenXMLDocument qui permettent d'explorer la structure du paquetage et d'accéder à ses parties sont toutes statiques, du fait que la fabrique a besoin d'accéder à ces méthodes pour déterminer le type du document alors qu'aucune classe du framework n'a encore été instanciée.
3. Le code PHP▲
Dans cette section sont passées en revue les principales parties qui composent le code du framework.
3-1. Lecture et recherche dans les fichiers de relations▲
Avant d'accéder à une partie, il est nécessaire de disposer de son nom en consultant le fichier de relation lié à la partie source à laquelle elle est liée (si la source est la racine du paquetage, elle est désignée par la constante OpenXMLDocument::ROOT_PARTNAME). Cette fonction est assurée par la méthode statique OpenXMLDocument::getRelationTarget() :
static function getRelationTarget(ZipArchive $zip, $sourcePartName, $relationURI) {
// Construction du nom du fichier de relations selon la norme OPC (Open Package Conventions)
$relation_file = dirname($sourcePartName) . '_rels/' . basename($sourcePartName) . '.rels';
// Normalisation du nom de fichier de relations : les \ renvoyés par dirname() si l'on travaille sur une plateforme Windows sont remplacés par des /
$relation_file = str_replace('\\', '/', $relation_file);
// On retire le / de tête, l'accès à un item zippé est toujours relatif à la racine de l'archive
if ($relation_file[0] == '/') {
$relation_file = substr($relation_file, 1);
}
$relations_xml = self::xml_getPart($zip, $relation_file);
if (empty($relations_xml)) {
throw new OpenXMLFatalException('Impossible de parser le fichier des relations', __METHOD__);
}
$relations_xml->registerXPathNamespace('rns', self::RELATIONSHIPS_NS);
$relation_targets = $relations_xml->xpath("/rns:Relationships/rns:Relationship[@Type='$relationURI']/@Target");
if (empty($relation_targets) or count($relation_targets) == 0) {
throw new OpenXMLException('Impossible de localiser la cible de la relation ' . $relationURI, __METHOD__);
}
return $relation_targets[0];
}la première tâche de cette méthode est de reconstituer le nom du fichier de relations, à partir du nom de la partie source (pour la description de la règle qui définit le nom d'un fichier de relation, voir la section 1.4 de l'article Structure d'un document OpenXML). Une fois ce nom connu, le fichier de relations est ouvert et parsé par la méthode OpenXMLDocument::xml_getPart(), qui renvoie un objet SimpleXMLElement. La cible (target) de la relation est ensuite retrouvée grâce une requête XPath dont l'URI de la relation sert d'argument.
La lecture proprement dite des parties est effectuée par la méthode OpenXMLDocument::xml_getPart() :
static function xml_getPart(ZipArchive $zip, $partName, $ns = NULL) {
$part_content = $zip->getFromName($partName);
if (empty($part_content)) {
throw new OpenXMLFatalException('Impossible de lire la partie ' . $partName, __METHOD__);
}
$xml = simplexml_load_string($part_content, NULL, NULL, $ns, FALSE);
if (empty($xml)) {
throw new OpenXMLFatalException('Impossible de parser la partie ' . $partName, __METHOD__);
}
return $xml;
}La seule chose remarquable dans cette méthode est le nombre assez inhabituel de paramètres passés à la fonction simplexml_load_string() ; le paramètre $ns, qui contient un espace de nom (URI), est nécessaire pour pouvoir lire les documents XML dont l'élément racine (document element) est préfixé par un alias d'espace de noms. C'est le cas de la partie XML contenant les métadonnées du document (voir plus loin).
3-2. Détermination du type de document▲
L'instanciation de la classe concrète de document est assurée par la méthode statique OpenXMLDocumentFactory::openDocument(), qui doit être la première méthode du framework appelée par le code client :
static function openDocument($fileName) {
$zip = new ZipArchive();
if ($zip->open($fileName) !== TRUE) {
throw new OpenXMLFatalException('Impossible d\'ouvrir le fichier ' . $fileName, __METHOD__);
}
// On recherche le Content Type de la partie principale du document
$type = OpenXMLDocument::getMainPartContentType($zip);
$zip->close();
// On instancie et on retourne la classe concrète de document correspondant au type de contenu
switch ($type) {
case OpenXMLDocument::WORD_DOCUMENT_CONTENT_TYPE:
return new WordDocument($fileName);
break;
case OpenXMLDocument::EXCEL_WORKBOOK_CONTENT_TYPE:
return new ExcelWorkbook($fileName);
break;
default:
throw new OpenXMLFatalException('Le type de document ' . $type . ' est inconnu', __METHOD__);
}
}Pour identifier le type du document, cette méthode fabrique s'appuie sur deux méthodes statiques de OpenXMLDocument :
static function getMainPartContentType(ZipArchive $zip) {
$main_part = self::getRelationTarget($zip, self::ROOT_PARTNAME, self::OFFICE_DOCUMENT_ROOT_REL);
$type = self::getContentType($zip, $main_part);
return $type;
}
static function getContentType(ZipArchive $zip, $partName) {
$contents_xml = self::xml_getPart($zip, '[Content_Types].xml');
$contents_xml->registerXPathNamespace('cns', self::CONTENT_TYPES_NS);
$types = $contents_xml->xpath("/cns:Types/cns:Override[@PartName = '/$partName']/@ContentType");
if (empty($types) or count($types) == 0) {
// On n'a pas trouvé d'élément Override correspondant à la partie recherchée
// On recherche donc parmi les types par défaut, celui correspondant à l'extension de la partie
$extension = substr(strrchr($partName, '.'), 1);
$types = $contents_xml->xpath("/cns:Types/cns:Default[@Extension = '$extension']/@ContentType");
if (empty($types) or count($types) == 0) {
throw new OpenXMLException('Impossible de déterminer le type de contenu de ' . $partName, __METHOD__);
} else {
return $types[0];
}
} else {
return $types[0];
}
}OpenXMLDocument::getMainPartContentType() retourne le type MIME de la partie contenant le corps du document, et OpenXMLDocument::getContentType() retourne le type MIME de la partie dont le nom lui est passé en paramètre.
3-3. Lecture des métadonnées▲
La lecture des métadonnées est assurée par la méthode OpenXMLDocument::readCoreProperties() :
private function readCoreProperties() {
$corePropertiesPartName = self::getRelationTarget($this->zip, self::ROOT_PARTNAME, self::CORE_PROPERTIES_REL);
$document = self::xml_getPart($this->zip, $corePropertiesPartName, self::CORE_PROPERTIES_NS);
$this->keywords = $document->keywords;
$this->last_writer = $document->lastModifiedBy;
$this->revision = $document->revision;
$dc_elements = $document->children(self::DUBLIN_CORE_NS);
$this->creator = $dc_elements->creator;
$dc_elements = $document->children(self::DUBLIN_CORE_TERMS_NS);
$this->date_modified = $dc_elements->modified;
$this->date_created = $dc_elements->created;
}La structure de la partie contenant les métadonnées du document nous oblige à quelques acrobaties avec SimpleXML. En effet, les éléments contenant les métadonnées sont réparties entre trois espaces de noms, comme le montre cet exemple :
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<cp:coreProperties
xmlns:cp="http://schemas.openxmlformats.org/package/2006/metadata/core-properties"
xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:dcmitype="http://purl.org/dc/dcmitype/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<dc:title>Manipulation des fichiers OpenXML avec PHP</dc:title>
<dc:subject>Programmation<dc:/subject>
<dc:creator>Eric Grimois</dc:creator>
<cp:keywords>OpenXML,PHP,framework,OPC</cp:keywords>
<dc:description>Description du format OpenXML et d'un framework PHP permettant sa manipulation</dc:description>
<cp:lastModifiedBy>Eric Grimois</cp:lastModifiedBy>
<cp:revision>2</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2007-01-15T15:44:00Z</dcterms:created>
<dcterms:modified xsi:type="dcterms:W3CDTF">2007-01-28T18:44:00Z</dcterms:modified>
</cp:coreProperties>L'élément racine du document, coreProperties, est préfixé par un alias. L'espace de noms vers lequel cet alias pointe doit être obligatoirement passé en paramètre à simplexml_load_string() (au travers de xml_getPart()), sous peine de voir cette fonction renvoyer NULL. Les autres éléments sont accessibles par l'intermédiaire de la méthode simpleXMLElement::children() à laquelle on passe en paramètre l'espace de noms auxquels ils appartiennent.
3-4. Lecture des propriétés étendues▲
La localisation et la récupération de la partie comprenant les propriétés dites "étendues" du document est effectuée par la méthode OpenXMLDocument::xml_getExtendedProperties() :
protected function xml_getExtendedProperties() {
$extendedPropertiesPartName = self::getRelationTarget($this->zip, self::ROOT_PARTNAME, self::EXTENDED_PROPERTIES_REL);
return self::xml_getPart($this->zip, $extendedPropertiesPartName);
}Par contre, la lecture des informations qui se trouvent dans cette partie est spécifique à chaque classe concrète de document. D'un schéma moins complexe que celui décrivant les métadonnées, cette partie se laisse plus facilement manipuler par SimpleXML. Pour la classe WordDocument, c'est la méthode WordDocument::getExtendedProperties() qui s'en charge :
function readExtendedProperties() {
$document = parent::xml_getExtendedProperties();
$this->application = $document->Application;
$this->nb_paragraphs = $document->Paragraphs;
$this->nb_characters = $document->Characters;
$this->nb_characters_with_spaces = $document->CharactersWithSpaces;
$this->nb_pages = $document->Pages;
$this->nb_words = $document->Words;
}3-5. Transformation XSLT▲
C'est la méthode OpenXMLDocument::getXSLTTransformedDocument() qui se charge de transformer la partie principale du document selon la feuille de style passée en paramètre :
protected function getXSLTTransformedDocument($stylesheetName) {
$xsl = new XSLTProcessor();
$stylesheet = new DOMDocument();
if ($stylesheet->load($stylesheetName) == FALSE) {
throw new OpenXMLFatalException('Impossible de charger la feuille de style ' . $stylesheet, __METHOD__);
}
$xsl->importStyleSheet($stylesheet);
$mainPartName = self::getRelationTarget($this->zip, self::ROOT_PARTNAME, self::OFFICE_DOCUMENT_ROOT_REL);
$mainPartContent = $this->zip->getFromName($mainPartName);
if (empty($mainPartContent)) {
throw new OpenXMLFatalException('Impossible de lire la partie ' . $partName, __METHOD__);
}
$document = new DOMDocument();
if ($document->loadXML($mainPartContent) == FALSE) {
throw new OpenXMLFatalException('Impossible de charger la partie principale du document', __METHOD__);
}C'est la seule méthode du framework qui nécessite l'usage de DOM. Cependant, cet usage se limite ici au chargement du document à transformer et à celui de la feuille de style.
La transformation s'opère uniquement sur la partie principale du document (main part), et le framework n'autorise pas, dans sa conception actuelle, l'accès à d'autres parties du document, telles celles contenant l'entête et le pied de page par exemple. Il serait nécessaire, dans un framework complet, de prévoir un mécanisme pour que le processeur XSLT puisse atteindre n'importe quelle partie du document à partir de la partie principale.
Au niveau de chaque classe fille de OpenXMLDocument, la transformation est utilisée par la méthode getHTMLPreview() pour renvoyer un extrait du document.
function getHTMLPreview() {
return parent::getXSLTTransformedDocument('preview-word.xslt');
}La feuille de style est évidemment spécifique à chaque type de document. L'utilisation de XSLT et donc la séparation d'avec le code PHP permet à cette présentation d'être totalement modifiable sans craindre pour l'intégrité du code du framework. La feuille de style associée aux documents Word, très sommaire, se contente de renvoyer le premier paragraphe non vide :
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/3/main"
exclude-result-prefixes="w">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes" omit-xml-declaration="yes"/>
<xsl:template match="/">
<p>
<xsl:value-of select="w:document/w:body/w:p[normalize-space(.) != ''][1]"/>
</p>
</xsl:template>
</xsl:stylesheet>L'espace de noms http://schemas.openxmlformats.org/wordprocessingml/2006/3/main est utilisé par les fichiers Word générés par la version Beta 2 de Office 2007 (c'est également la version des fichiers exemples fournis avec le framework) ; si vous employez la version stable de Office 2007, remplacez dans la feuille de style cet espace de nom par le définitif : http://schemas.openxmlformats.org/wordprocessingml/2006/main
Pour lui garder sa simplicité, ce framework ne présente pas de preview pour les classeurs Excel.
4. Exemple d'application▲
Voici un exemple simple d'application exploitant ce framework :
<?php
require_once('openxml.class.php');
$documents = array('sample1.docx', 'sample1.xlsx');
foreach ($documents as $document) {
echo "<b><u>$document</u></b><br/>";
try {
$mydoc = OpenXMLDocumentFactory::openDocument($document);
echo '<br/><i>Metadonnées :</i><br/><br/>';
echo 'Créateur: ' . $mydoc->getCreator() . '<br/>';
echo 'Sujet: ' . $mydoc->getSubject() . '<br/>';
echo 'Mots-clés: ' . $mydoc->getKeywords() . '<br/>';
echo 'Description: ' . $mydoc->getDescription() . '<br/>';
echo 'Date de création : ' . $mydoc->getCreationDate() . '</br>';
echo 'Date de dernière modification : ' . $mydoc->getLastModificationDate() . '<br/>';
echo 'Modifié en dernier par: ' . $mydoc->getLastWriter() . '<br/>';
echo 'Révision: ' . $mydoc->getRevision() . '<br/>';
echo '<br/><i>Propriétés du document:</i><br/><br/>';
echo 'Généré par: ' . $mydoc->getApplication() . '<br/>';
$document_class = get_class($mydoc);
if ($document_class == 'WordDocument') {
echo 'Nombre de paragraphes: ' . $mydoc->getNbOfParagraphs() . '<br />';
echo 'Nombre de caractères: ' . $mydoc->getNbOfCharacters() . '<br />';
echo 'Nombre de caractères (avec les espaces): ' . $mydoc->getNbOfCharactersWithSpaces() . '<br/>';
echo 'Nombre de pages: ' . $mydoc->getNbOfPages() . '<br/>';
echo 'Nombre de mots: ' . $mydoc->getNbOfWords() . '<br/>';
}
echo '<br/><i>Aperçu du document:</i> <br/>';
echo $mydoc->getHTMLPreview();
}
catch (OpenXMLFatalException $e) {
echo $e->getMessage();
}
echo '<br/><br/>';
}
?>Conclusion▲
Dans ce tutoriel, nous avons décrit un framework PHP permettant la lecture de fichiers Office 2007. Ce framework, bien que tout à fait fonctionnel, est assez rudimentaire ; il ne tient qu'à vous de l'étendre et de l'enrichir de vos idées.
Télécharger les sources du frameworktélécharger les sources
Quelques liens utiles :
Structure des fichiers OpenXMLStructure des fichiers OpenXML
Créer un fichier Word OpenXML (2007) avec .NET
Les spécifications OpenXML à l'ECMA
OpenXML Developer
Je remercie Yogui pour sa patiente relecture.